Expanding the idea of peer conversations as basis for IT decisions, I would like to extend a little bit the reasons for my belief that this trend will probably continue, and lend to some unexpected results.
Let’s start by thinking as a CIO that has to decide on a new technology, or in integrating a new software system in the company’s infrastructure. The only thing that the CIO knows is the fact that creating software from scratch is costly and requires a significant ongoing maintenance cost, so shifts the decision to a software platform from some vendor, and seeks advice on a company that may provide the necessary integration.
Using this limited information, what the CIO knows is that:
- there is a large number of potential platforms to choose from
.
- some may be more appropriate than others, and that choosing the wrong one may cause significant delays and added cost
.
- just browsing through the advertising material is not sufficient to choose in an appropriate way
.
- that the long-term viability of a company can only be guessed.
So, what is the best strategy? We can try to imagine what a perfectly rational CIO would do, that is it would create a probability tree and try to guess at the potential events, their probability, and their impact. So, for example, if we choose by ourselves, the probabilities may be:
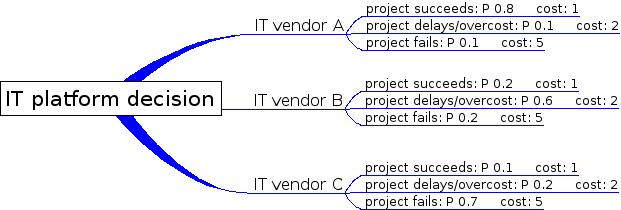
In this scenario, the CIO has to give an initial estimates at the probability of succeeding. How can she do it? By looking at similar tasks, for example. As most people uses Microsoft, or IBM, or SAP, she is fairly confident that she can use those too, and as those companies are still alive, they are probably doing it right. This is of course a false assumption, as there is limited information on failed or delayed project (outside the largest ones, like some government IT nightmares), but it is the only information that the CIO does have. Given this information, she knows that by choosing wisely, the potential cost of vendor A is 1.5, with vendor B is 2.4, with vendor C is 4. But she does not if the selection is appropriate, or if all the vendors have been included in the list.
We have also not considered what happens after the end of the project, like what happens if the company leaves the market, or decides to change the platform without giving enough time for a migration strategy, and so on; but we will leave this for a later post.
Now, let’s say that the CIO has already tried some projects, and discovered that she is unable to estimate probabilities with reasonable accuracy. At this point, she would probably go to a consultancy, that is an independent party with better information on the products, that has demonstrated to be able to select with more accuracy the appropriate probabilities. This is always advantageous, as long as the consultancy has an information advantage on the CIO; the price that she pays goes in a commensurate reduction in the risks associated with the project.
But what happens when the consultancy seems no more able than the CIO to select the platform, or when it is suspected that the suggestions are not entirely independent? Then, the CIO has no alternative than trying as much as possible to remain on the “tried and tested”, and hope that everything will continue to be fine.
What happened recently? The change is that the idea of openness and the availability of open forums allowed users to exchange information (sometimes even in an anonymous form), giving the CIO insight on what really works and what does not. This first hand information is for example what allowed many open source server projects to be deployed in a grass-roots fashion; because system administrators were exchanging information about them, and the best ones succeeded. Now this process is starting to be used at higher levels, and this goes back to the death of generalists conferences: as those do not allow for a venue for information exchange in a bilateral way, the users started feeling that it was not useful anymore when compared to web, second life, traditional marketing and so on.
So we suppose that users (CIOs) are more interested in conversations. But can a CIO base her own opinion on talking with strangers? The reality is that in a way similar to how Google PageRanks adjusts relevance, the user networks created on blogs, digg-like social sites, or unconferences are adjusting themselves for relevance, and allows trust to emerge from seemingly untrusted parties.
The concept is simple: let’s say that a user talks on a blog about his experience with a product, and other read about it. Around this post, may additional links may be created, some criticizing, some praising the text; and eventually, some users that share information often may become “daily reading material”. The usefulness, and reliability of the source can be inferred easily, by reading at the text itself, if the reasoning or the experience seems reasonable, and how others react to the post.
While it may be imaginable that one blogger may be paid for talking in a positive way about a product, it is difficult to imagine that *every* user is biased or unreliable, and we can read and verify even the dissenting views with ease. This way, “reliable” writers and experts can emerge for free, and the CIO can verify everything without paying a consultant to get the same information. Of course this does not means that errors do not happen – only that errors are public, and that it is possible for everyone to check any step or any information against public sources.
This is the real value that is arising from “web2.0” networks, that is the spontaneous creation of networks of peers, that can be trusted thanks to their transparency and willingness to cooperate. I can only guess that this form of value will be probably not be judged in a positive way by sellers, as this negates some lock-in advantage (the push for unified single-company platforms, for example); but this may be the only potential way to exit from a “lemon market” and giving back to the user the power to choose among products in an unbiased way.
[trust networks, peer discovery, open source]


 Choose by
Choose by  Best Practices by
Best Practices by  Unconference by
Unconference by {kind=link}
Reply